(06/2023 – 11/2023)
Authors: Pei-Xin Ye, Geng-Kai Wong, Samantha Shih, Pei-Hsin Chang, Yi-Hsiang Cheng, Chiun-Li Chin*
Presenter: Samantha Shih
Published paper in 2023 12th International Conference on Awareness Science and Technology (iCAST)

Research Paper Link
PowerPoint
Introduction
Hearing impairment (HI) is a chronic condition that often leads to communication barriers. This makes it especially hard for those with HI to seek healthcare services for their condition, worsening it. The World Health Organization estimates that there are more than 1.5 billion people who suffer from hearing impairment, and the number is projected to increase to almost 2.5 billion by 2050.
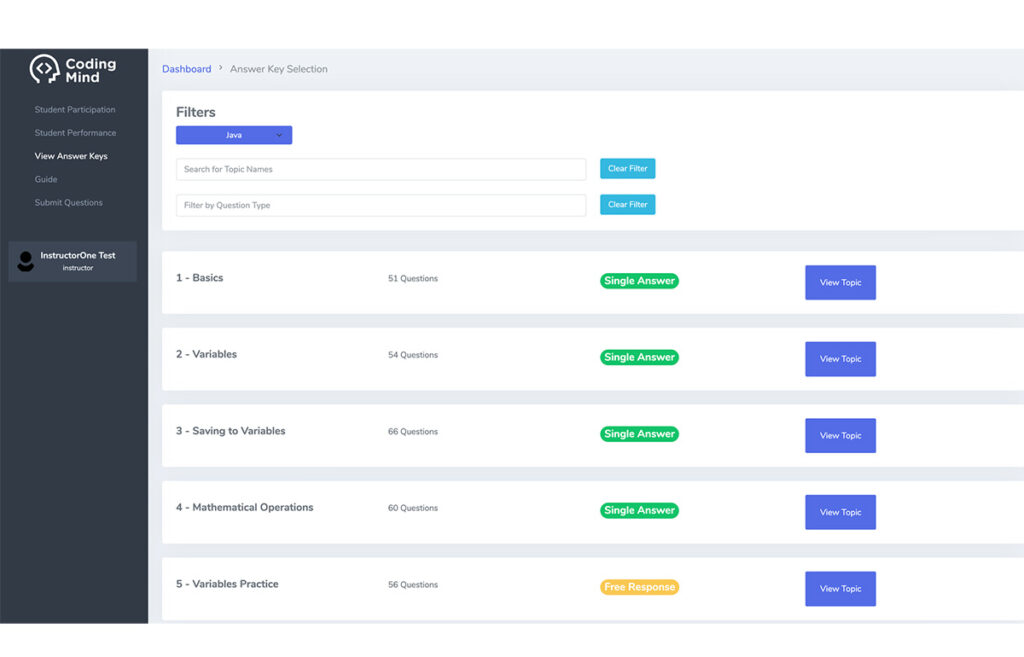
In this research, we proposed the concept of the Hearing Impairment Communication Assistive System (HICAS). HICAS is an innovative solution aimed at surmounting communication barriers confronted by the hearing-impaired. HICAS instantaneously records conversations between hearing-impaired individuals and others. It annotates keywords within the text context.
HICAS also employs advanced retrieval techniques to source pertinent location images from the Internet. It presents images using AR glasses. This innovative interface strives to effectively address the challenge of communication for people with HI. Specifically, we use HICAS to assist in communication between doctors and patients in order for them to receive proper treatment.
Related Works
In 2019, Stevens et al. highlighted the challenges for people with HI in communication, prompting the development of innovative solutions.
Also in 2019, Merkx and others found that speech-to-image (S2I) retrieval can effectively aid language learning. This allows hearing-impaired individuals to comprehend location images in conversations by visualizing the information.
In 2022, Ganesh et al. achieved an average error rate of only 17.165% for speech recognition. However, those with HI are often unable to grasp the keywords of the conversation regardless of whether they can read the text generated from speech.
Also in 2022, Kumar et al. applied a deep learning based audio visual speech recognition model and achieved a 95% accuracy and a 6.59% error rate. Due to the prevalence of face masks in hospitals, however, recognition based on lip-reading is not useful for patient-doctor interactions.
Notably, Lee et al. embedded speech-to-text (S2T) and Multichannel Acoustic Beamformer in portable devices, improving communication between the hearing-impaired and normal-hearing individuals. Nonetheless, the difficulty in capturing the pivotal details within discussions persists due to hearing loss.
In summary, the benefit of using HICAS for language learning and communication for those with HI is great. We are the first to propose such a solution.
Contributions
- Scholars have used S2T methods to improve communication, but have not highlighted keywords or used location images to further assist people with HI.
- We are the first to propose HICAS to assist in communication.
- Use of our method can reach an impressively high real-time image search accuracy during conversations.
- Thus, we can effectively help people with HI understand and engage in everyday conversations.
Method
System Diagram
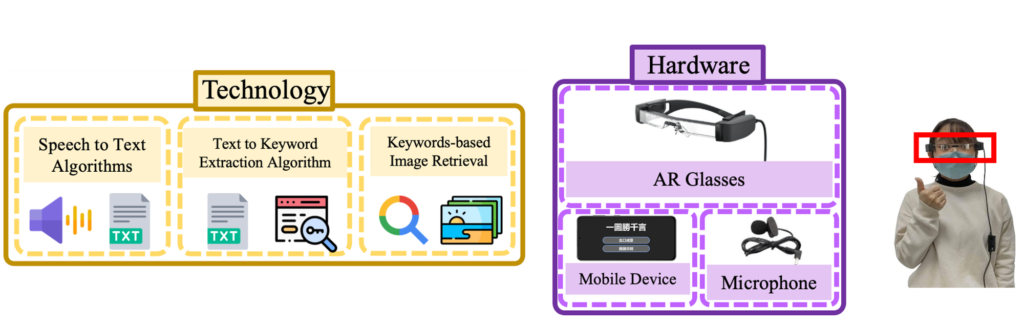
System Flowchart
Dataset
The dataset was self-collected with a size of around 100. It consists of common phrases that patients and doctors use to communicate, and was used to fine-tune the RoBERTa model for T2KE to be specific towards patient-doctor interactions. We involved 26 total participants to annotate keywords for the same text content.
Speech-to-Text (S2T)
First, the ESPNet framework was leveraged as the foundation to train an end-to-end Speech-To-Text (S2T) model. This framework was chosen because the primary goal is to convert speech input into text without relying on separate components, and ESPNet does this best. This streamlines the system construction process and achieves S2T functionality.
Text-to-Keyword Extraction (T2KE)
Pretrained weights of a RoBERTa model were employed as initial weights and were fine-tuned in order to be specific for communication between doctors and the hearing-impaired.
Saliency Maps were utilized to obtain gradients for each input token, categorizing sentences with location-related content. Keywords with high probabilities were extracted. The extracted keywords were based on what the 26 participants selected as keywords.
The Softmax activation function was applied at the output layer to label and extract keywords with high probabilities. This was chosen because it is multi-class, meaning that it produces a probability distribution across multiple classes. Our goal is to assign probabilities to different keywords, making this most suitable.
Keyword-based Image Retrieval (KBIR)
Keywords were treated as input for image queries, performing image searches through image retrieval.
A CRF probability model and MaxEnt classifier were used to calculate the optimal confidence. The option with the highest confidence as the output image result was selected.
The results were presented to users through AR glasses, combining text and image outcomes.
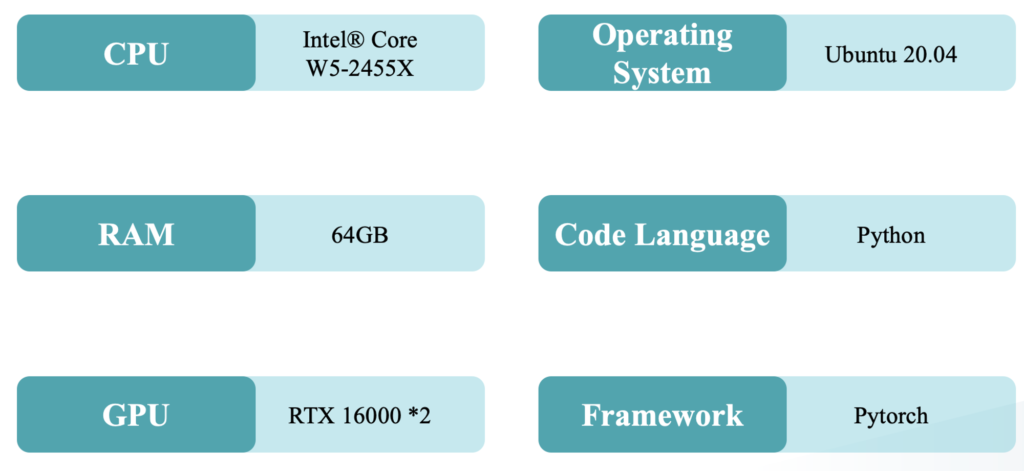
Environment Settings
Results
To validate whether the HICAS system could assist HI individuals in improving communication difficulties, tests were conducted on both HI individuals and the elderly. Through experimental results, we found that the accuracy of S2T conversion reached up to 90.57%.
For T2KE, 26 participants annotated keywords for the same text content, resulting in a keyword similarity of approximately 81.34%.
In the KBIR component, real-time image retrieval from conversations took approximately 0.8 to 1.5 seconds, achieving an accuracy of about 94.62%.
Discussion
In the future, HICAS can be applied to everyday language outside of just communicating with doctors, in order to better assist hearing-impaired individuals. The limited dataset may be a factor reducing the accuracy. Therefore, in the future, the accuracy can likely be raised by increasing the size of the dataset. Because 26 participants are not especially representative of the general population, a larger number of participants can be involved in order to make the result more generalizable.
Conclusion
This paper proposes a HICAS with S2I functionality to address communication difficulties faced by individuals with hearing impairment and their challenges in capturing key points in paragraphs or sentences. Based on experimental results, the system demonstrates promising data outcomes, including a 94.62% accuracy in KBIR, affirming its effective assistance for users. Through HICAS, communication content with others, conversation highlights, and images related to Hearing Care Center location can be conveniently and visually accessed.